EmoSteer-TTS: Fine-Grained and Training-Free Emotion-Controllable
Text-to-Speech via Activation Steering
Tianxin Xie1, Shan Yang2, Chenxing Li2,
Dong Yu2, Li Liu1
1HKUST(GZ), 2Tencent
Abstract
Text-to-speech (TTS) has shown great progress in recent years. However,
most existing TTS systems offer only coarse and rigid emotion control,
typically via discrete emotion labels or a carefully crafted and
detailed emotional text prompt, making fine-grained emotion manipulation
either inaccessible or unstable. These models also require extensive,
high-quality datasets for training. To address these limitations, we
propose EmoSteer-TTS, a novel
training-free approach, to achieve
fine-grained speech emotion control (conversion,
interpolation, erasure) by activation steering. We
first empirically observe that modifying a subset of the internal
activations within a flow matching-based TTS model can effectively alter
the emotional tone of synthesized speech. Building on this insight, we
then develop a training-free and efficient algorithm, including
activation extraction, emotional token searching, and inference-time
steering, which can be seamlessly integrated into a wide range of
pretrained models (e.g., F5-TTS, CosyVoice2, and E2-TTS). In addition,
to derive effective steering vectors, we construct a curated emotional
speech dataset with diverse speakers. Extensive experiments demonstrate
that EmoSteer-TTS enables fine-grained, interpretable, and continuous
control over speech emotion, outperforming the state-of-the-art (SOTA).
To the best of our knowledge, this is the first method that achieves
training-free and continuous fine-grained emotion control in TTS. Demo
samples are available at
https://emosteer-tts.pages.dev/.
Note: The content on this page is for research purposes only.
Method Framework
Our EmoSteer-TTS approach enables training-free and fine-grained emotion
control through activation steering:
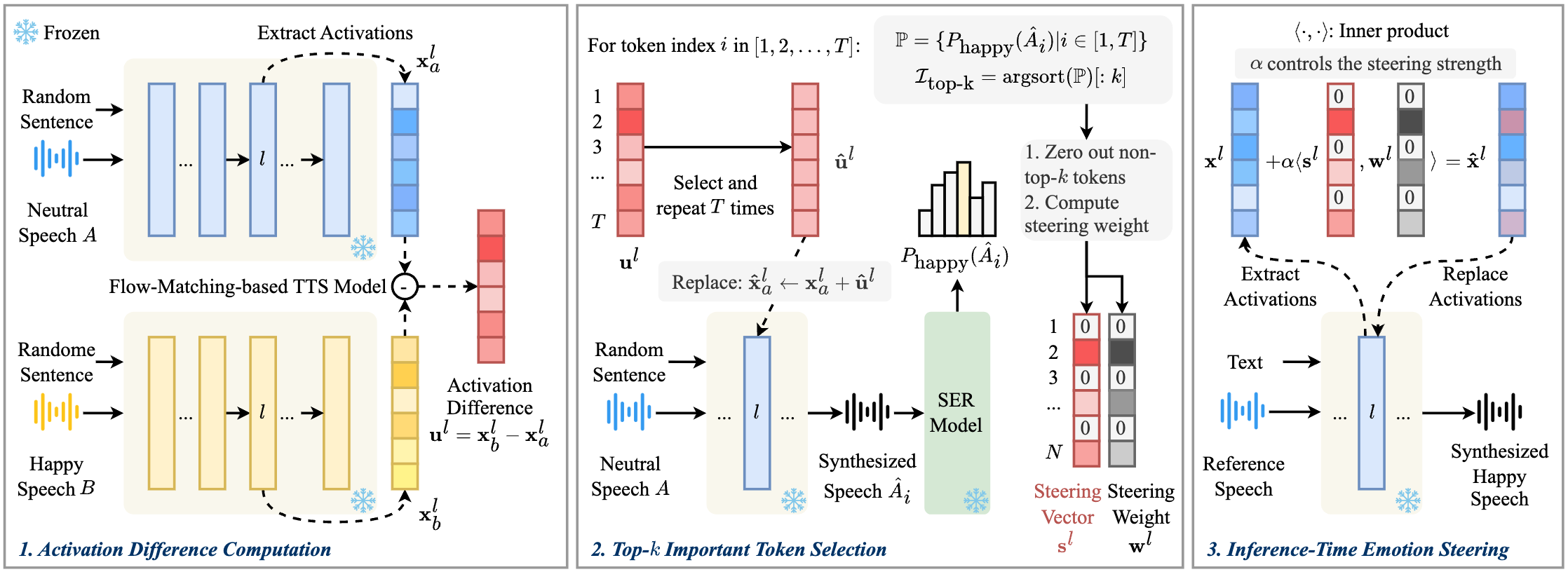
Figure 1: Overview of the proposed EmoSteer-TTS. Emotion steering
vectors and steering weights are derived from pairs of neutral and
emotional reference speech samples. During inference, these vectors
are used to modulate the activations of the TTS model, effectively
guiding it to synthesize speech that reflects the desired
emotion.
Contributions
We present the first fine-grained and training-free
emotion-controllable TTS (EC-TTS) approach by identifying and
modulating internal emotion representations within existing TTS
models.
We provide new insights and enhanced interpretability for continuous
EC-TTS by uncovering the emotion steering dynamics in pretrained TTS
models, offering practical guidance for the design of the proposed
algorithm.
Extensive objective and subjective evaluations demonstrate the
effectiveness of EmoSteer-TTS in fine-grained speech emotion
control, showing its potential applicability across a wide range of
pretrained TTS models.
Training-Free Emotion Conversion
Emotion conversion supports six basic emotions: anger, disgust, fear,
happiness, sadness, and surprise.
Target Emotion: Anger
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
我都快气疯了你怎么还这么冷静
E2-TTS + EmoSteer-TTS
You had one job and you still managed to screw it up.
CosyVoice2 + EmoSteer-TTS
Completely ridiculous. I can't stay quiet anymore!
Target Emotion: Disgust
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
这种人我听着都觉得恶心
E2-TTS + EmoSteer-TTS
It's disgusting how fake people can be in these discussions.
CosyVoice2 + EmoSteer-TTS
That arrogant attitude is absolutely revolting.
Target Emotion: Fear
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
这些照片看着怪怪的让我浑身发冷
E2-TTS + EmoSteer-TTS
Something about this doesn't feel right at all.
CosyVoice2 + EmoSteer-TTS
I wish I could pretend I'm not frightened, but I am.
Target Emotion: Happiness
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
今天阳光真好一切都让人心情愉快
E2-TTS + EmoSteer-TTS
I feel so grateful and cheerful right now.
CosyVoice2 + EmoSteer-TTS
That news just made my day. I can't stop smiling.
Target Emotion: Sadness
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
我努力了,却还是让人失望了
E2-TTS + EmoSteer-TTS
Who is repeating all that hard stuff to you?
CosyVoice2 + EmoSteer-TTS
I wish conversations like this didn't remind me of what's missing.
Target Emotion: Surprise
Method
Reference Audio (Neutral)
Text
Synthesized ($\alpha$=2.0)
F5-TTS + EmoSteer-TTS
我简直不敢相信会发生这种事
E2-TTS + EmoSteer-TTS
That's surprising. I had no idea he wrote so much!
CosyVoice2 + EmoSteer-TTS
I'm honestly shocked by how much that covers.
Training-Free Emotion Interpolation
EmoSteer-TTS can also interpolate between a neutral reference and a
target emotion to create a smooth transition:
Target Emotion: Anger
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
你到底能不能小心点?每次都出问题!
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
This is absolutely unacceptable!
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
How many times do I have to tell you.
0.0 (Neutral)
0.5
1.0
1.5
2.0
Target Emotion: Disgust
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
这种天气真是让人讨厌到极点。
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
That's just disgusting.I don't even want to think about it.
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
I can't stand being around this kind of behavior.
0.0 (Neutral)
0.5
1.0
1.5
2.0
Target Emotion: Fear
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
这声音太诡异了,我不敢一个人待在这。
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
Something about this doesn't feel right at all.
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
I couldn't sleep at all. I was too anxious.
0.0 (Neutral)
0.5
1.0
1.5
2.0
Target Emotion: Happiness
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
不过现在天气放晴了,心情也跟着亮了!
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
I feel so grateful and cheerful right now!
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
We've been laughing all day. It's been wonderful!
0.0 (Neutral)
0.5
1.0
1.5
2.0
Target Emotion: Sadness
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
天气恶劣让我感到无助和害怕。
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
The squire himself showed perfect.
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
Take courage all isn't lost yet.
0.0 (Neutral)
0.5
1.0
1.5
2.0
Target Emotion: Surprise
Reference Audio (Neutral)
Text
Steering Intensity ($\alpha$)
Synthesized
F5-TTS + EmoSteer-TTS
天哪,居然需要重新做一遍
0.0 (Neutral)
0.5
1.0
1.5
2.0
E2-TTS + EmoSteer-TTS
I can't believe what I've just heard.
0.0 (Neutral)
0.5
1.0
1.5
2.0
CosyVoice2 + EmoSteer-TTS
Wow! I didn't expect there to be so few activists!
0.0 (Neutral)
0.5
1.0
1.5
2.0
The Emotion Interpolation Ability of Training-Based Baseline Methods
All the samples are grabbed from their official demo pages.
EmoSphere++ (Cho et al. 2025) offers intensity control
over four emotions, i.e., Anger, Happiness, Sadness, and Surprise.
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Anger
Weak
Happiness
Weak
Sadness
Weak
Surprise
Weak
Medium
Medium
Medium
Medium
Strong
Strong
Strong
Strong
HED-TTS (Inoue et al. 2025) offers intensity control
over four emotions, i.e., Anger, Happiness, Sadness, and Surprise.
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Anger
0.0
Happiness
0.0
Sadness
0.0
Surprise
0.0
0.4
0.4
0.4
0.4
0.6
0.6
0.6
0.6
1.0
1.0
1.0
1.0
EmoDubber (Cong et al. 2025) offers intensity control
over three emotions, i.e., Anger, Sadness, and Surprise.
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Emotion
Intensity
Synthesized
Anger
Weak
Sadness
Zero
Surprise
Zero
Medium
Strong
Strong
Strong
Training-Free Emotion Erasure
EmoSteer-TTS can also erase the emotion of a reference speech to create
a neutral speech:
Emotion to Erase: Anger
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
我觉得并不是非要有特别的品质
E2-TTS + EmoSteer-TTS
What am I? I'm a racer, son of God!
CosyVoice2 + EmoSteer-TTS
Hurry up, hurry up!
Emotion to Erase: Disgust
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
It doesn't make any sense. But then again, what in the government
does make sense?
E2-TTS + EmoSteer-TTS
Oh yeah. Yeah, no, there's a horrifying moment. I think the guy's
from Time or something. I tried to interview him. It's crass. It's
in bad.
CosyVoice2 + EmoSteer-TTS
Oh, it looks so terrible. I don't think I want this, but it's...
Emotion to Erase: Fear
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
So there are huge amounts of danger. I'm very worried because...
Continue to share important stuff with me on Facebook.
E2-TTS + EmoSteer-TTS
Maybe it's old school, but I don't see how that's any of my
business. Okay.
CosyVoice2 + EmoSteer-TTS
That world. You're going to hide inside yourself, crying. You'll
flood as much of the world to drown me.
Emotion to Erase: Happiness
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
我已经习惯这种气候了
E2-TTS + EmoSteer-TTS
裁判全给了满分
CosyVoice2 + EmoSteer-TTS
and vowed he'd change the pigtail's place.
Emotion to Erase: Sadness
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
我一直到清晨四点才到家
E2-TTS + EmoSteer-TTS
比如说华尔街日报就很好
CosyVoice2 + EmoSteer-TTS
Fur flew through the air, teeth gnashed.
Emotion to Erase: Surprise
Method
Before Erasure (($\beta$=0.0))
Text
After Erasure ($\beta$=2.5)
F5-TTS + EmoSteer-TTS
This is Jack, the relatives of Tom?
E2-TTS + EmoSteer-TTS
Tom now let our arrows fly?
CosyVoice2 + EmoSteer-TTS
不是很喜欢你把我绕晕了
Training-Free Multi-Emotion Steering
EmoSteer-TTS enables simultaneously adding two emotions to the
synthesized speech. All the examples below are generated using the
F5-TTS backbone.
Note: Oversteered (e.g., $\alpha$ > 2.0) samples may exhibit
artifacts, noise, pitch and timbre change, or unnaturalness.
Emotions to Add: Anger and Sadness
Reference Audio (Neutral)
Text
$\alpha_{anger}$
$\alpha_{sadness}$
Multi-Emotion Steered
你到底能不能小心点?每次都出问题!
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
How many times do I have to tell you?
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
Emotions to Add: Anger and Disgust
Reference Audio (Neutral)
Text
$\alpha_{anger}$
$\alpha_{disgust}$
Multi-Emotion Steered
你别总拿别人当借口!
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
I'm tired of repeating myself over and over!
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
Emotions to Add: Fear and Surprise
Note: You may need to adjust the volume levels for better listening
experience.
Reference Audio (Neutral)
Text
$\alpha_{fear}$
$\alpha_{surprise}$
Multi-Emotion Steered
这声音太诡异了,我不敢一个人待在这。
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
I'm afraid of what they might say.
0.0
0.0
2.0
0.0
2.0
1.0
2.0
2.0
2.0
3.0
2.0
4.0
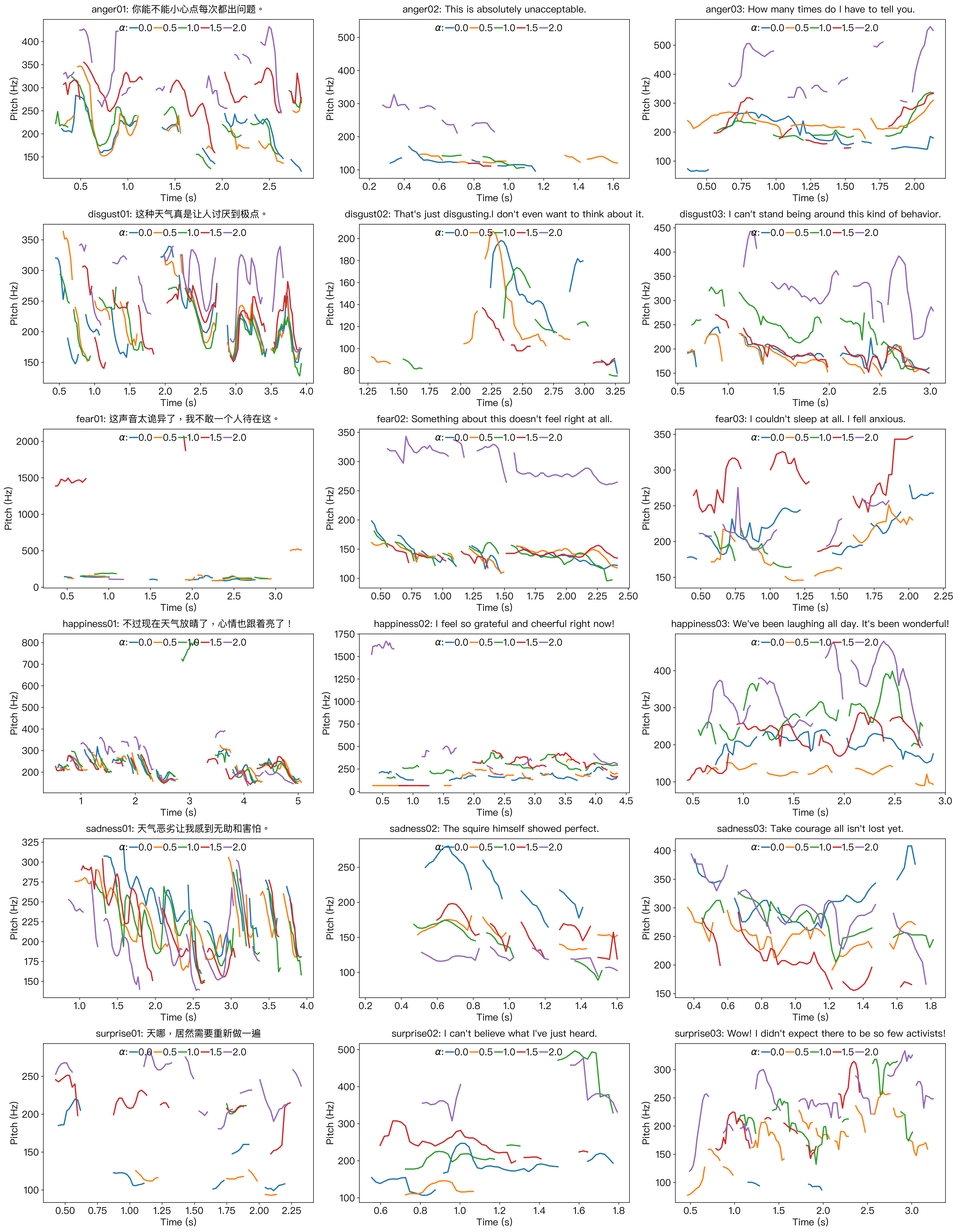
Visualization of F0 Transition
Emotion Interpolation
In this subsection, we present additional visualizations of F0 contours
to illustrate the fine-grained and continuous emotion interpolation
capabilities of the proposed EmoSteer-TTS. As shown in Figure 2, voices
with angrier, happier, or more surprised tones tend to exhibit higher
pitch, while sadder tones are generally associated with lower pitch. In
contrast, pitch variations in disgust and fear interpolation show no
clear monotonic trend, which we attribute to the fact that these
emotions are more closely tied to semantic content than to acoustic
characteristics.
Figure 2: Visualizations of F0 contours in emotion interpolation.
From left to right: F5-TTS, E2-TTS, and CosyVoice2. From top to
bottom: anger, disgust, fear, happiness, sadness, and surprise. All
the synthesized speech samples are interpolated between neutrality
($\alpha$=0) and a target emotion ($\alpha$=2).
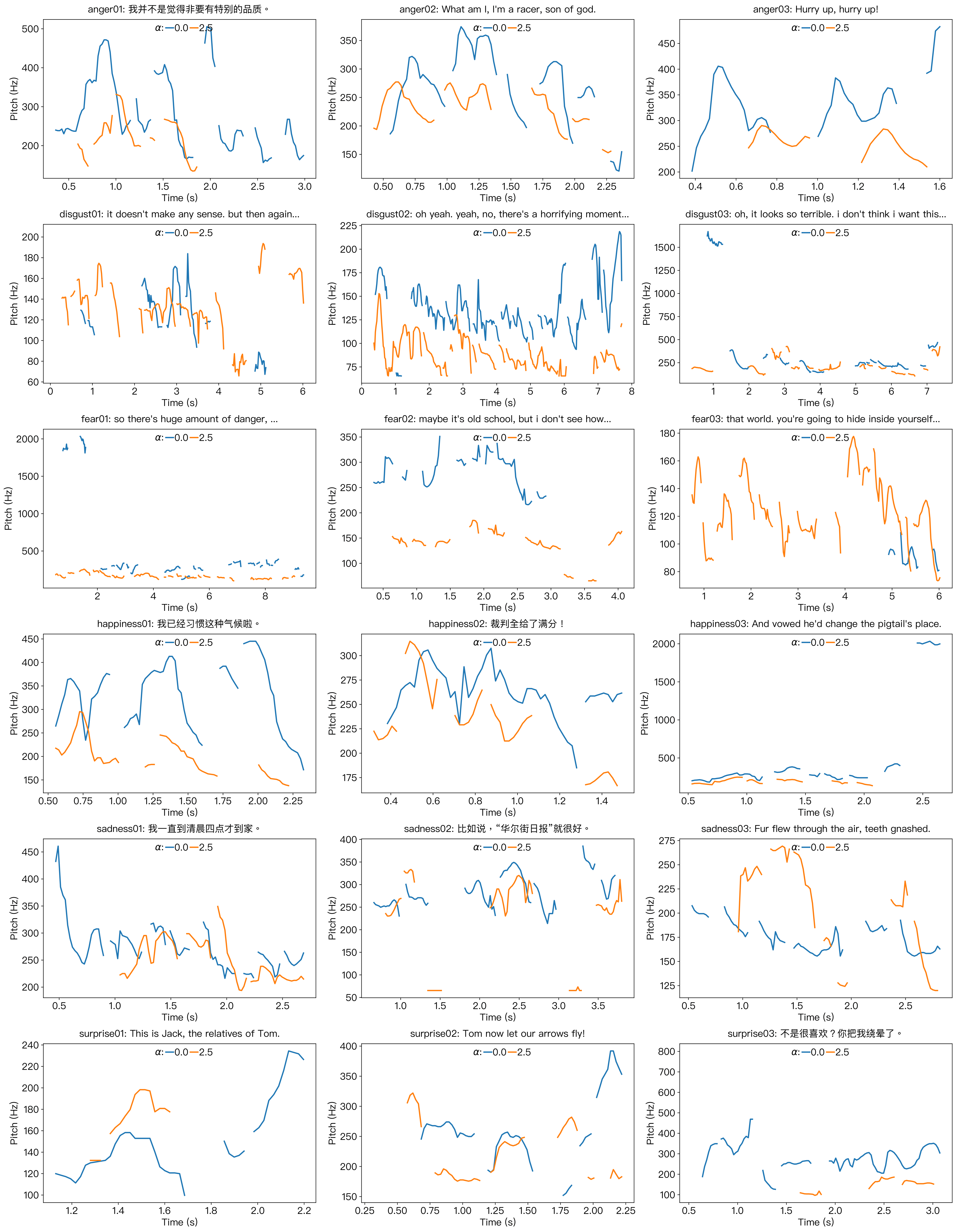
Emotion Erasure
In this subsection, we present additional F0 contour visualizations to
demonstrate the emotion erasure capability of the proposed EmoSteer-TTS.
As shown in Figure 3, the pitch contours of angry, disgusted, happy, and
surprised voices become noticeably flatter after emotion erasure,
indicating a calmer prosodic pattern. In contrast, the changes in pitch
for fear and sadness are more diverse and less predictable. This
variability may stem from the fact that fear can be expressed through
multiple vocal styles, such as a low, trembling voice or a high-pitched
scream, making it difficult for pitch alone to capture the underlying
emotional shift. Similarly, sadness may manifest as either soft weeping
or loud crying, resulting in inconsistent pitch patterns that do not
reliably reflect emotional intensity.
Figure 3: Visualizations of F0 contours in emotion erasure. From
left to right: F5-TTS, E2-TTS, and CosyVoice2. From top to bottom:
anger, disgust, fear, happiness, sadness, and surprise. All the
synthesized speech samples are emotionally erased from a target
emotion ($\beta$=0) towards neutrality ($\beta$=2.5).
Conclusion
We presented EmoSteer-TTS, the first training-free framework for
fine-grained, continuous, and interpretable emotion control in speech
synthesis. By steering a subset of internal activations in a TTS model,
our method enables flexible emotional manipulation, including emotion
conversion, interpolation, and erasure, without modifying or fine-tuning
the pretrained TTS model. We also constructed a curated emotional speech
dataset to support steering vector construction. Extensive experiments
confirm that EmoSteer-TTS achieves robust, zero-shot emotion control
with broad applicability, outperforming SOTA methods. The analysis also
offers deeper insights into the emotion steering dynamics of flow
matching-based TTS. To the best of our knowledge, this is the first
fine-grained EC-TTS approach that can transform previously
uncontrollable TTS models into emotionally controllable ones without any
retraining, fine-tuning, or model redesign.